
Education
I am a Ph.D. student in the School of Computer Science at Peking University (PKU),
where I have been studying since 2021 under the guidance of Prof. Bin Cui.
I received my Bachelor's degree from Peking University in 2021.
Research Interest
My research interest primarily lies in Distributed Deep/Machine Learning Systems (DL/MLSys), Infrastructure for Large Language Models (LLM Infra).
In recent years, I mainly focus on:
(1) Parallelism optimization for LLMs training;
(2) Efficient long-context training;
(3) Multi-task, multi-modality training acceleration;
(4) Memory management and communication optimization in distributed systems.
Currently, I am also interested in:
(1) Mixture-of-Experts (MoE) Models training and inference optimization;
(2) Post-training and reinforcement learning systems (RL Infra);
(3) Diffusion models training and inference optimization.
Publications
I have published 10 papers in top-tier CCF-A conferences and journals (4 first-authored papers and 2 second-authored papers), including ASPLOS, VLDB, SIGMOD, SOSP, TKDE, ICLR, ICCV, SIGKDD, and etc.
I also have 2 recent papers under review.
Details of Publications
System Projects
I am the designer, project leader, and main developer of Hetu-Galvatron,
an open-source automatic parallel training system optimized for LLMs.
I am also a core developer of Hetu, a high-performance distributed deep learning system.
Details of System Projects
Industrial Applications
My works and systems have been applied in billion-scale industrial applications, such as accelerating the training of LLMs with over 100B parameters,
and has been utilized by companies like HUAWEI, ZTE, Alibaba, and etc.
Currently, I am also collaborating with more industrial companies to deploy and further develop these systems, such as ByteDance and Baidu.
Warning
Problem: The current name of your GitHub Pages repository ("Solution: Please consider renaming the repository to "
http://".
However, if the current repository name is intended, you can ignore this message by removing "{% include widgets/debug_repo_name.html %}" in index.html.
Action required
Problem: The current root path of this site is "baseurl ("_config.yml.
Solution: Please set the
baseurl in _config.yml to "Education
-
 Peking UniversitySchool of Computer Science
Peking UniversitySchool of Computer Science
Ph.D. Candidate, advised by Prof. Bin Cui2021 - present -
Peking UniversityB.Sc (Bachelor of Science) in Computer Science and Technology2017 - 2021
Experience
-
 Hetu Team, PKU-DAIR (Data and Intelligence Research Lab), Peking University[System Researcher]
Hetu Team, PKU-DAIR (Data and Intelligence Research Lab), Peking University[System Researcher]
- Project leader, designer and main developer of Hetu-Galvatron, an open-source LLM automatic parallel training system.
- Core developer of Hetu, a high-performance distributed DL system.2019 - present -
 ByteDance, Seed Group - CV - AI Platform[Infrastructure Research Intern]
ByteDance, Seed Group - CV - AI Platform[Infrastructure Research Intern]
- Development of scalable and robust LLMs training infrastructure.
- Design and development of FlexSP, a high-performance long-context LLM training system supporting flexible sequence parallelism.2025 - present -
 Alibaba Cloud, PAI (Platform of Artificial Intelligence)[System Research Intern]
Alibaba Cloud, PAI (Platform of Artificial Intelligence)[System Research Intern]
- Research on accelerating large-scale multi-task (MT) multi-modality (MM) model training.
- Design and development of Spindle, an efficient distributed training system for large-scale multi-task (MT) multi-modality (MM) model.2023 - 2024
Honors & Awards
-
Peking University Merit Student | 北京大学三好学生2024
-
Peking University XIAOMI Scholarship | 北京大学小米奖学金2023
-
Peking University Merit Student | 北京大学三好学生2023
-
Peking University Outstanding Graduate | 北京大学优秀毕业生2021
-
Peking University Second-class Scholarship | 北京大学二等奖学金2020
-
Peking University Merit Student | 北京大学三好学生2020
-
Peking University Golden Arowana Scholarship | 北京大学金龙鱼奖学金2019
-
Peking University Merit Student | 北京大学三好学生2019
-
Peking University Founder Scholarship | 北京大学方正奖学金2018
-
Peking University Merit Student | 北京大学三好学生2018
News
Selected Publications (view all )
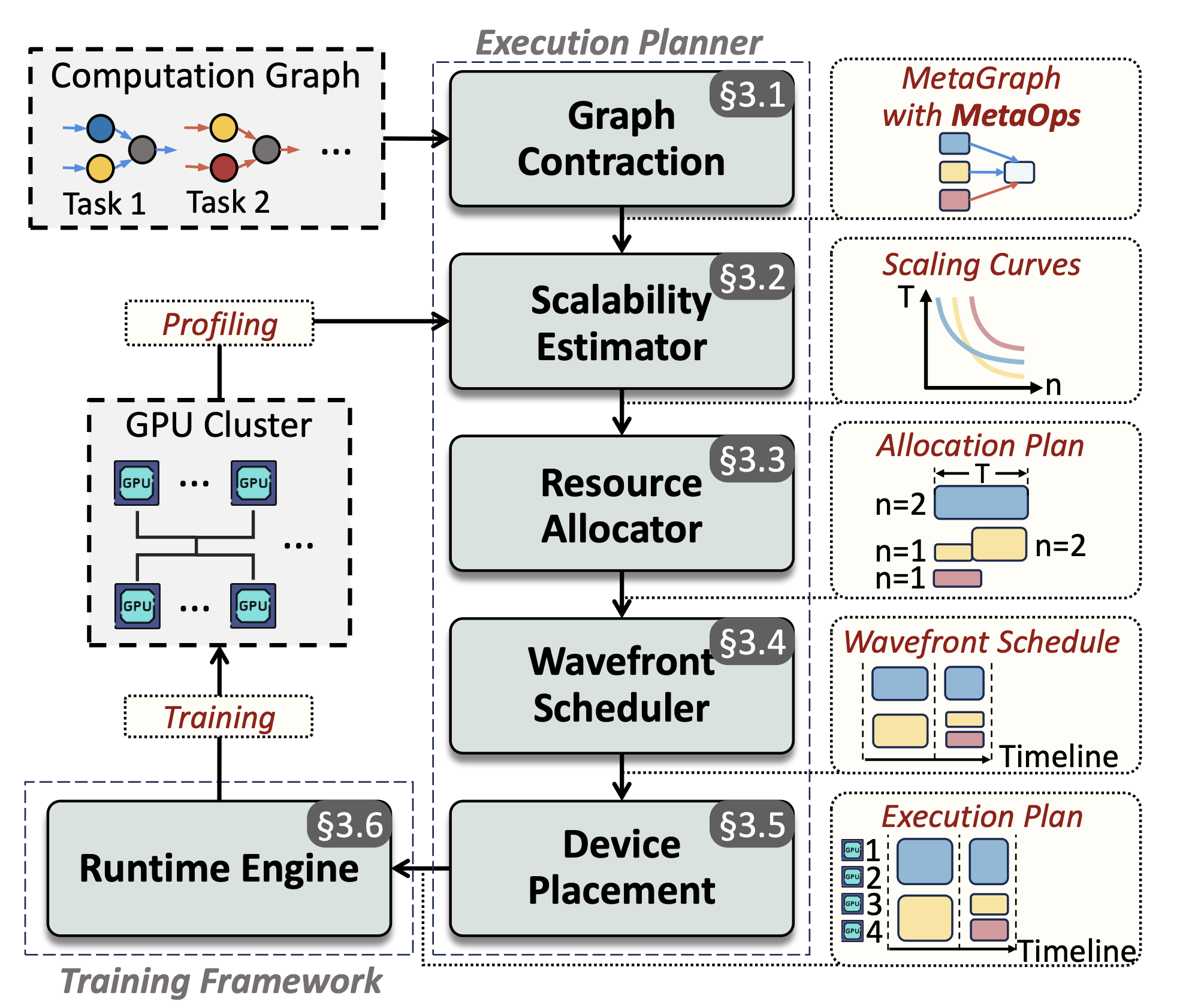
Spindle: Efficient Distributed Training of Multi-Task Large Models via Wavefront Scheduling
Yujie Wang, Shenhan Zhu, Fangcheng Fu, Xupeng Miao, Jie Zhang, Juan Zhu, Fan Hong, Yong Li, Bin Cui
[ASPLOS 2025 (CCF-A) | First Author] ACM International Conference on Architectural Support for Programming Languages and Operating Systems 2025
Multi-task (MT) multi-modal (MM) models pose significant challenges due to the sophisticated model architecture and the heterogeneous workloads of different ML tasks and data modalities. We propose Spindle, a new training system tailored for resource-efficient and high-performance training of MT MM models via wavefront scheduling. The key idea of Spindle is to decompose the MT MM model execution into waves and address the joint optimization problem sequentially, including both heterogeneity-aware workload parallelization and dependency-driven execution scheduling.
Spindle: Efficient Distributed Training of Multi-Task Large Models via Wavefront Scheduling
Yujie Wang, Shenhan Zhu, Fangcheng Fu, Xupeng Miao, Jie Zhang, Juan Zhu, Fan Hong, Yong Li, Bin Cui
[ASPLOS 2025 (CCF-A) | First Author] ACM International Conference on Architectural Support for Programming Languages and Operating Systems 2025
Multi-task (MT) multi-modal (MM) models pose significant challenges due to the sophisticated model architecture and the heterogeneous workloads of different ML tasks and data modalities. We propose Spindle, a new training system tailored for resource-efficient and high-performance training of MT MM models via wavefront scheduling. The key idea of Spindle is to decompose the MT MM model execution into waves and address the joint optimization problem sequentially, including both heterogeneity-aware workload parallelization and dependency-driven execution scheduling.
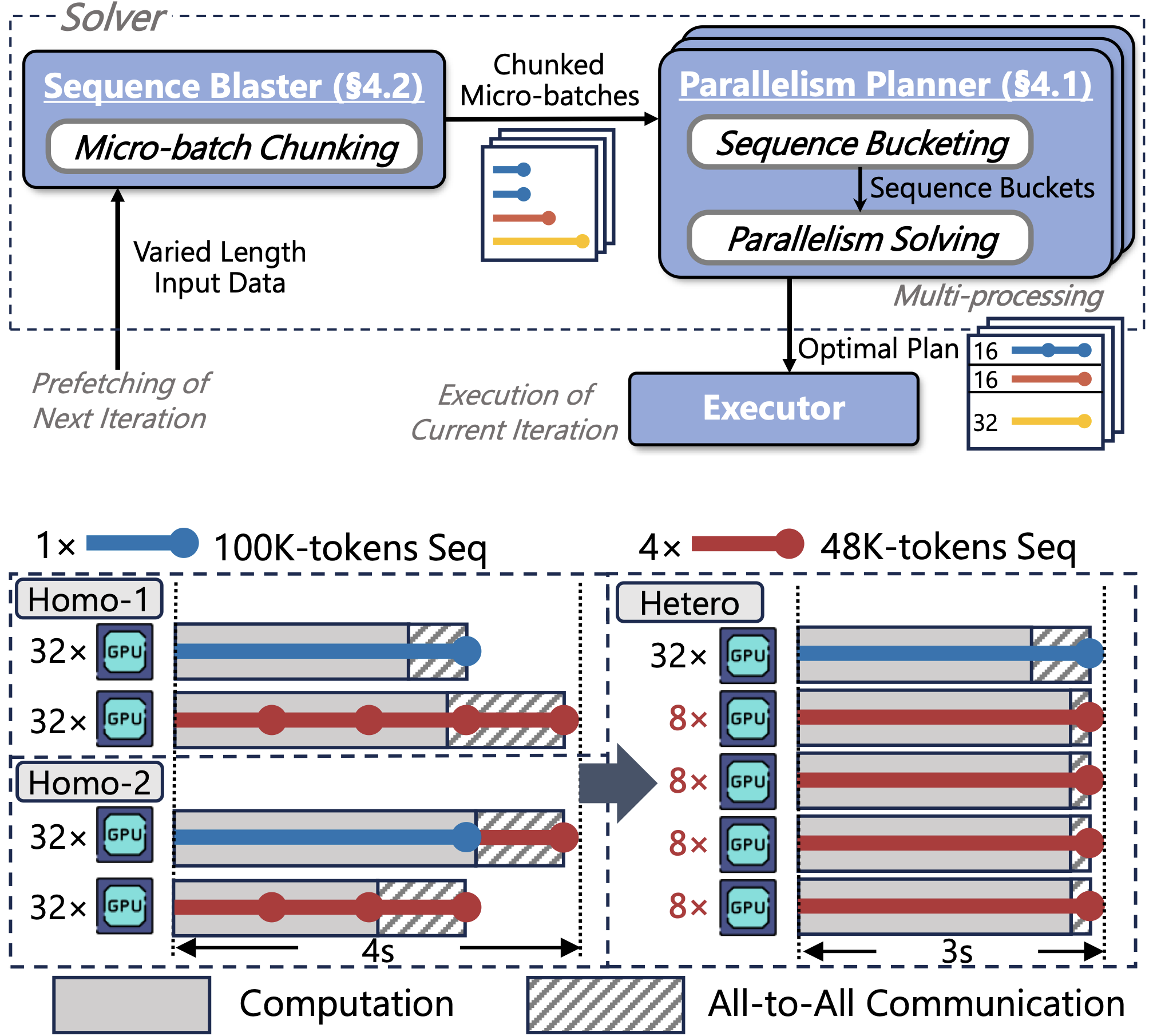
FlexSP: Accelerating Large Language Model Training via Flexible Sequence Parallelism
Yujie Wang, Shiju Wang, Shenhan Zhu, Fangcheng Fu, Xinyi Liu, Xuefeng Xiao, Huixia Li, Jiashi Li, Faming Wu, Bin Cui
[ASPLOS 2025 (CCF-A) | First Author] ACM International Conference on Architectural Support for Programming Languages and Operating Systems 2025
Sequence parallelism has been popular for training long-context LLMs. Existing methods assume homogeneous sequence lengths and leverages a single, static strategy. However, real-world training corpora exhibit variability in sequence lengths, leading to workload heterogeneity. We show that current methods suffers from inefficiency, and propose a heterogeneity-adaptive sequence parallelism method, which captures the variability in sequence lengths and assigns the optimal combination of scattering strategies based on workload characteristics.
FlexSP: Accelerating Large Language Model Training via Flexible Sequence Parallelism
Yujie Wang, Shiju Wang, Shenhan Zhu, Fangcheng Fu, Xinyi Liu, Xuefeng Xiao, Huixia Li, Jiashi Li, Faming Wu, Bin Cui
[ASPLOS 2025 (CCF-A) | First Author] ACM International Conference on Architectural Support for Programming Languages and Operating Systems 2025
Sequence parallelism has been popular for training long-context LLMs. Existing methods assume homogeneous sequence lengths and leverages a single, static strategy. However, real-world training corpora exhibit variability in sequence lengths, leading to workload heterogeneity. We show that current methods suffers from inefficiency, and propose a heterogeneity-adaptive sequence parallelism method, which captures the variability in sequence lengths and assigns the optimal combination of scattering strategies based on workload characteristics.
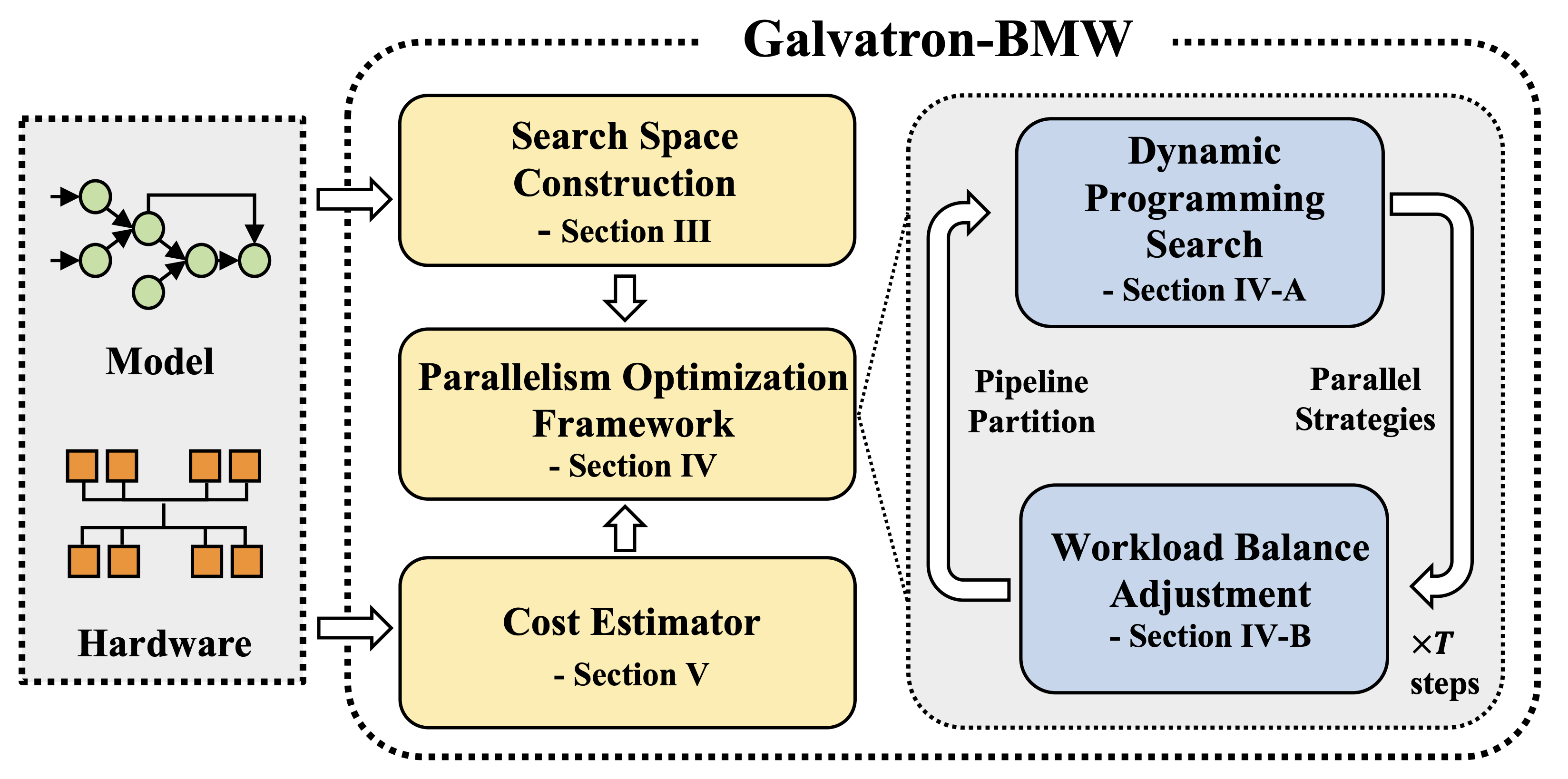
Improving Automatic Parallel Training via Balanced Memory Workload Optimization
Yujie Wang, Youhe Jiang, Xupeng Miao, Fangcheng Fu, Shenhan Zhu, Xiaonan Nie, Yaofeng Tu, Bin Cui
[TKDE 2024 (CCF-A) | First Author] IEEE Transactions on Knowledge and Data Engineering 2024
Efficiently training Transformer models across multiple GPUs remains a complex challenge due to the abundance of parallelism options. In this paper, we present Galvatron-BMW, a novel system framework that integrates multiple prevalent parallelism dimensions, which not only targets automatic parallelism optimization for large-scale Transformer models training, but also considers the Balancing trade-off between Memory and computation Workloads across devices through a novel bi-objective optimization framework. Experiments demonstrate the efficiency of our system.
Improving Automatic Parallel Training via Balanced Memory Workload Optimization
Yujie Wang, Youhe Jiang, Xupeng Miao, Fangcheng Fu, Shenhan Zhu, Xiaonan Nie, Yaofeng Tu, Bin Cui
[TKDE 2024 (CCF-A) | First Author] IEEE Transactions on Knowledge and Data Engineering 2024
Efficiently training Transformer models across multiple GPUs remains a complex challenge due to the abundance of parallelism options. In this paper, we present Galvatron-BMW, a novel system framework that integrates multiple prevalent parallelism dimensions, which not only targets automatic parallelism optimization for large-scale Transformer models training, but also considers the Balancing trade-off between Memory and computation Workloads across devices through a novel bi-objective optimization framework. Experiments demonstrate the efficiency of our system.
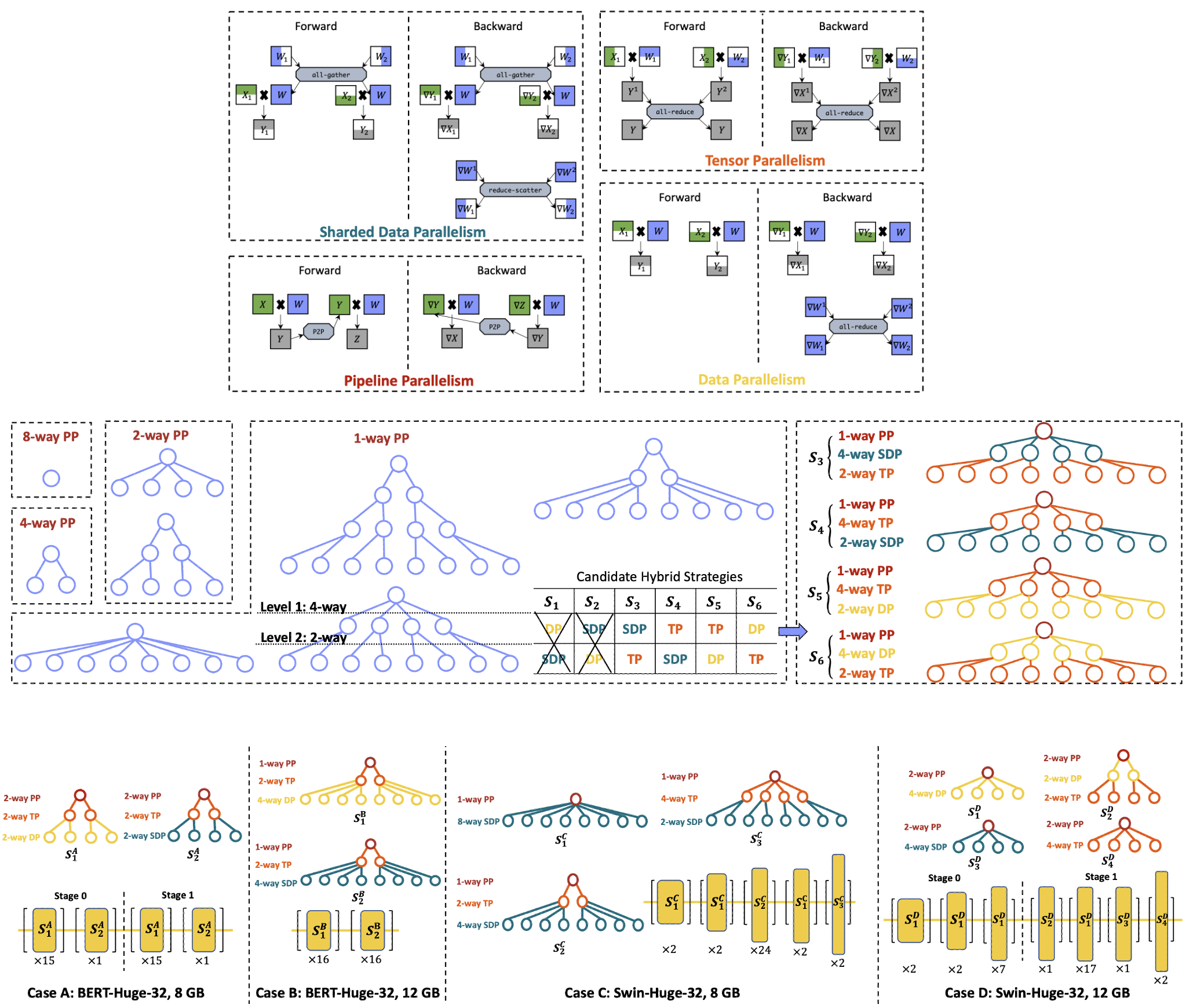
Galvatron: Efficient Transformer Training over Multiple GPUs Using Automatic Parallelism
Xupeng Miao*, Yujie Wang*, Youhe Jiang*, Chunan Shi, Xiaonan Nie, Hailin Zhang, Bin Cui (* equal contribution)
[VLDB 2023 (CCF-A) | Co-First Author] Proceedings of the VLDB Endowment 2023
To train large Transformer models over multiple GPUs efficiently, we propose Galvatron, a new automatic parallelism system that incorporates multiple popular parallelism dimensions and automatically finds the most efficient hybrid parallelism strategy. To better explore such a rarely huge search space, we 1) involve a decision tree to make decomposition and pruning based on some reasonable intuitions, and then 2) design a dynamic programming search algorithm to generate the optimal plan. Experiments show the effectiveness and efficiency of Galvatron.
Galvatron: Efficient Transformer Training over Multiple GPUs Using Automatic Parallelism
Xupeng Miao*, Yujie Wang*, Youhe Jiang*, Chunan Shi, Xiaonan Nie, Hailin Zhang, Bin Cui (* equal contribution)
[VLDB 2023 (CCF-A) | Co-First Author] Proceedings of the VLDB Endowment 2023
To train large Transformer models over multiple GPUs efficiently, we propose Galvatron, a new automatic parallelism system that incorporates multiple popular parallelism dimensions and automatically finds the most efficient hybrid parallelism strategy. To better explore such a rarely huge search space, we 1) involve a decision tree to make decomposition and pruning based on some reasonable intuitions, and then 2) design a dynamic programming search algorithm to generate the optimal plan. Experiments show the effectiveness and efficiency of Galvatron.