2025
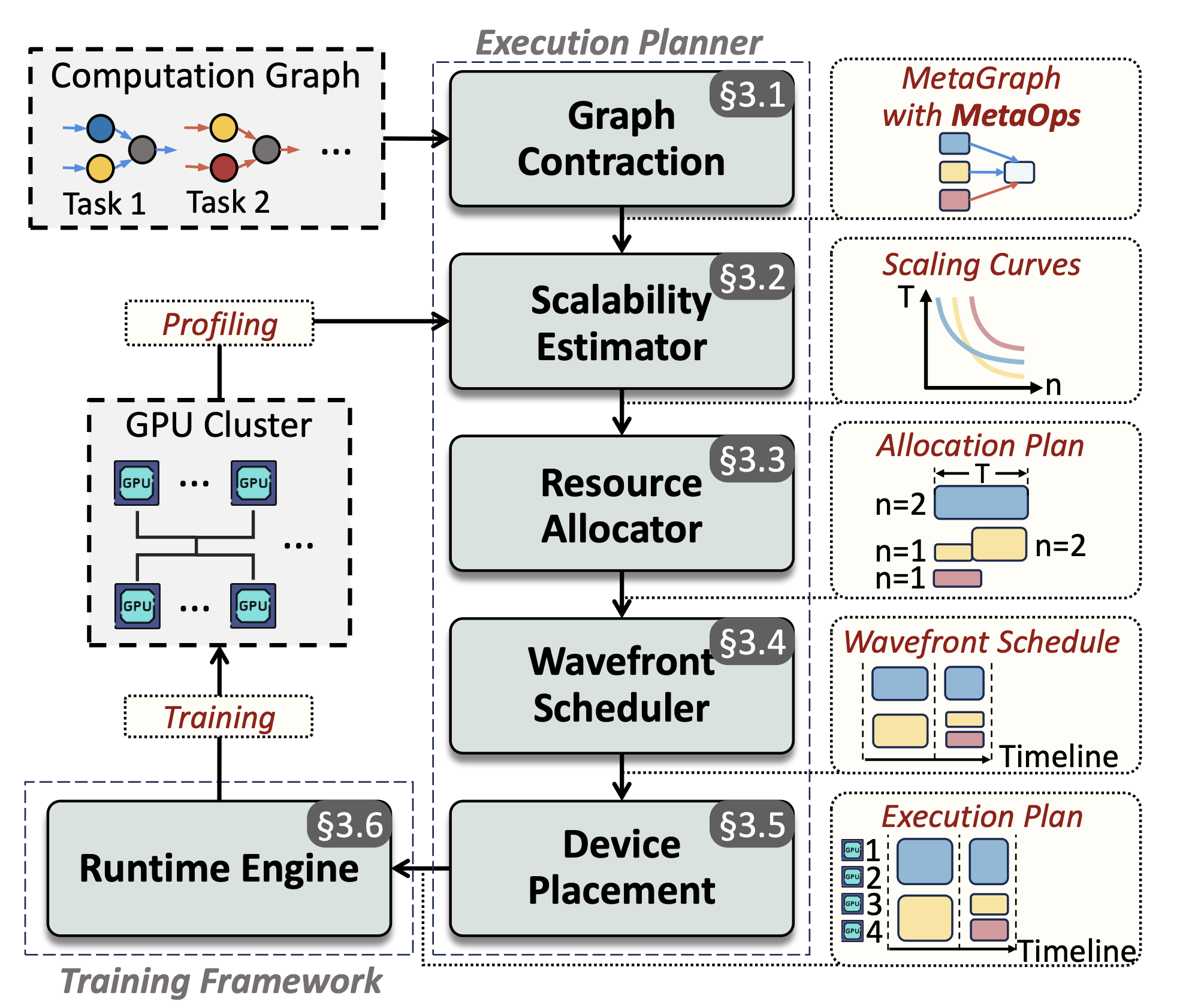
Spindle: Efficient Distributed Training of Multi-Task Large Models via Wavefront Scheduling
Yujie Wang, Shenhan Zhu, Fangcheng Fu, Xupeng Miao, Jie Zhang, Juan Zhu, Fan Hong, Yong Li, Bin Cui
[ASPLOS 2025 (CCF-A) | First Author] ACM International Conference on Architectural Support for Programming Languages and Operating Systems 2025
Multi-task (MT) multi-modal (MM) models pose significant challenges due to the sophisticated model architecture and the heterogeneous workloads of different ML tasks and data modalities. We propose Spindle, a new training system tailored for resource-efficient and high-performance training of MT MM models via wavefront scheduling. The key idea of Spindle is to decompose the MT MM model execution into waves and address the joint optimization problem sequentially, including both heterogeneity-aware workload parallelization and dependency-driven execution scheduling.
Spindle: Efficient Distributed Training of Multi-Task Large Models via Wavefront Scheduling
Yujie Wang, Shenhan Zhu, Fangcheng Fu, Xupeng Miao, Jie Zhang, Juan Zhu, Fan Hong, Yong Li, Bin Cui
[ASPLOS 2025 (CCF-A) | First Author] ACM International Conference on Architectural Support for Programming Languages and Operating Systems 2025
Multi-task (MT) multi-modal (MM) models pose significant challenges due to the sophisticated model architecture and the heterogeneous workloads of different ML tasks and data modalities. We propose Spindle, a new training system tailored for resource-efficient and high-performance training of MT MM models via wavefront scheduling. The key idea of Spindle is to decompose the MT MM model execution into waves and address the joint optimization problem sequentially, including both heterogeneity-aware workload parallelization and dependency-driven execution scheduling.
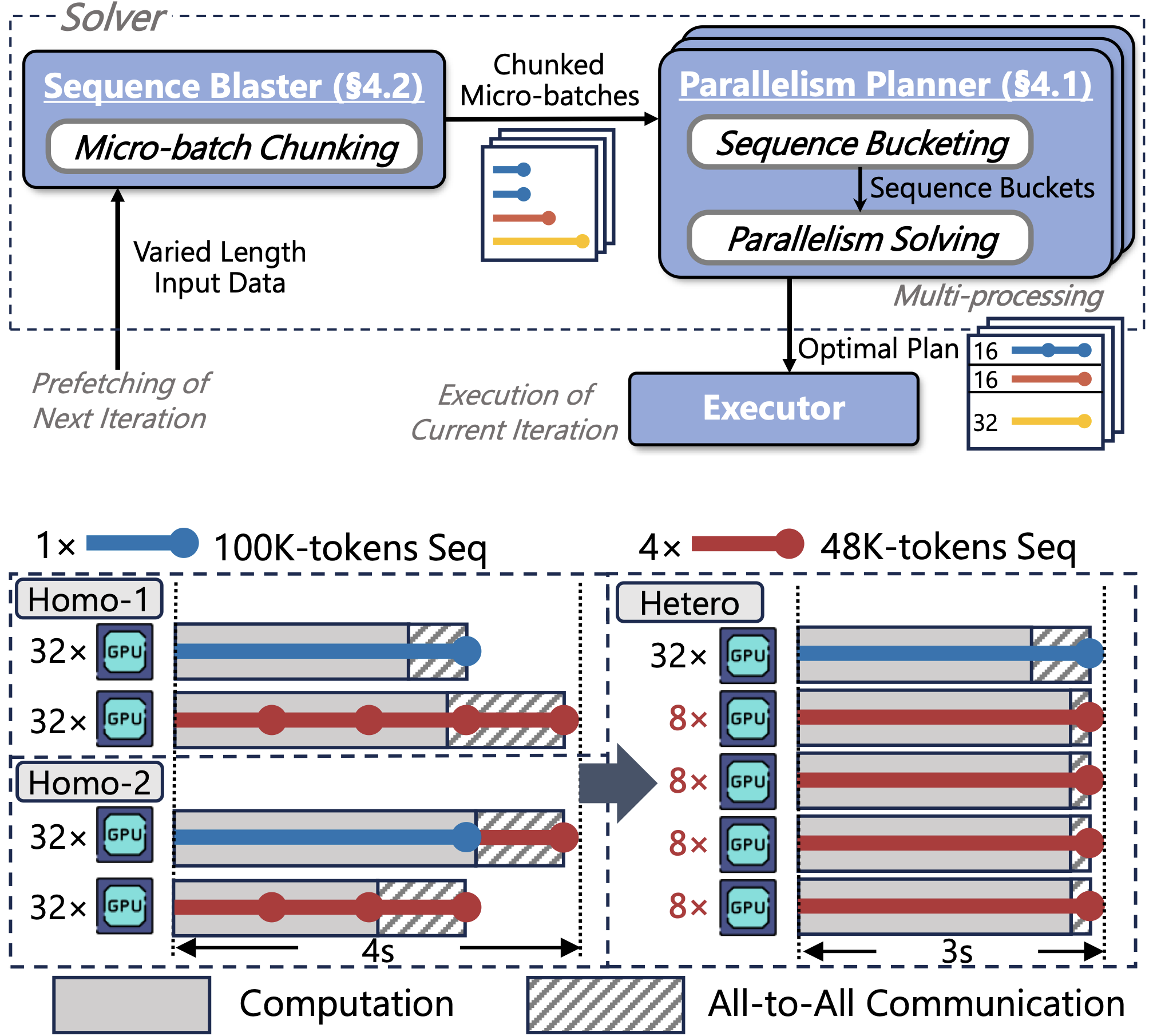
FlexSP: Accelerating Large Language Model Training via Flexible Sequence Parallelism
Yujie Wang, Shiju Wang, Shenhan Zhu, Fangcheng Fu, Xinyi Liu, Xuefeng Xiao, Huixia Li, Jiashi Li, Faming Wu, Bin Cui
[ASPLOS 2025 (CCF-A) | First Author] ACM International Conference on Architectural Support for Programming Languages and Operating Systems 2025
Sequence parallelism has been popular for training long-context LLMs. Existing methods assume homogeneous sequence lengths and leverages a single, static strategy. However, real-world training corpora exhibit variability in sequence lengths, leading to workload heterogeneity. We show that current methods suffers from inefficiency, and propose a heterogeneity-adaptive sequence parallelism method, which captures the variability in sequence lengths and assigns the optimal combination of scattering strategies based on workload characteristics.
FlexSP: Accelerating Large Language Model Training via Flexible Sequence Parallelism
Yujie Wang, Shiju Wang, Shenhan Zhu, Fangcheng Fu, Xinyi Liu, Xuefeng Xiao, Huixia Li, Jiashi Li, Faming Wu, Bin Cui
[ASPLOS 2025 (CCF-A) | First Author] ACM International Conference on Architectural Support for Programming Languages and Operating Systems 2025
Sequence parallelism has been popular for training long-context LLMs. Existing methods assume homogeneous sequence lengths and leverages a single, static strategy. However, real-world training corpora exhibit variability in sequence lengths, leading to workload heterogeneity. We show that current methods suffers from inefficiency, and propose a heterogeneity-adaptive sequence parallelism method, which captures the variability in sequence lengths and assigns the optimal combination of scattering strategies based on workload characteristics.
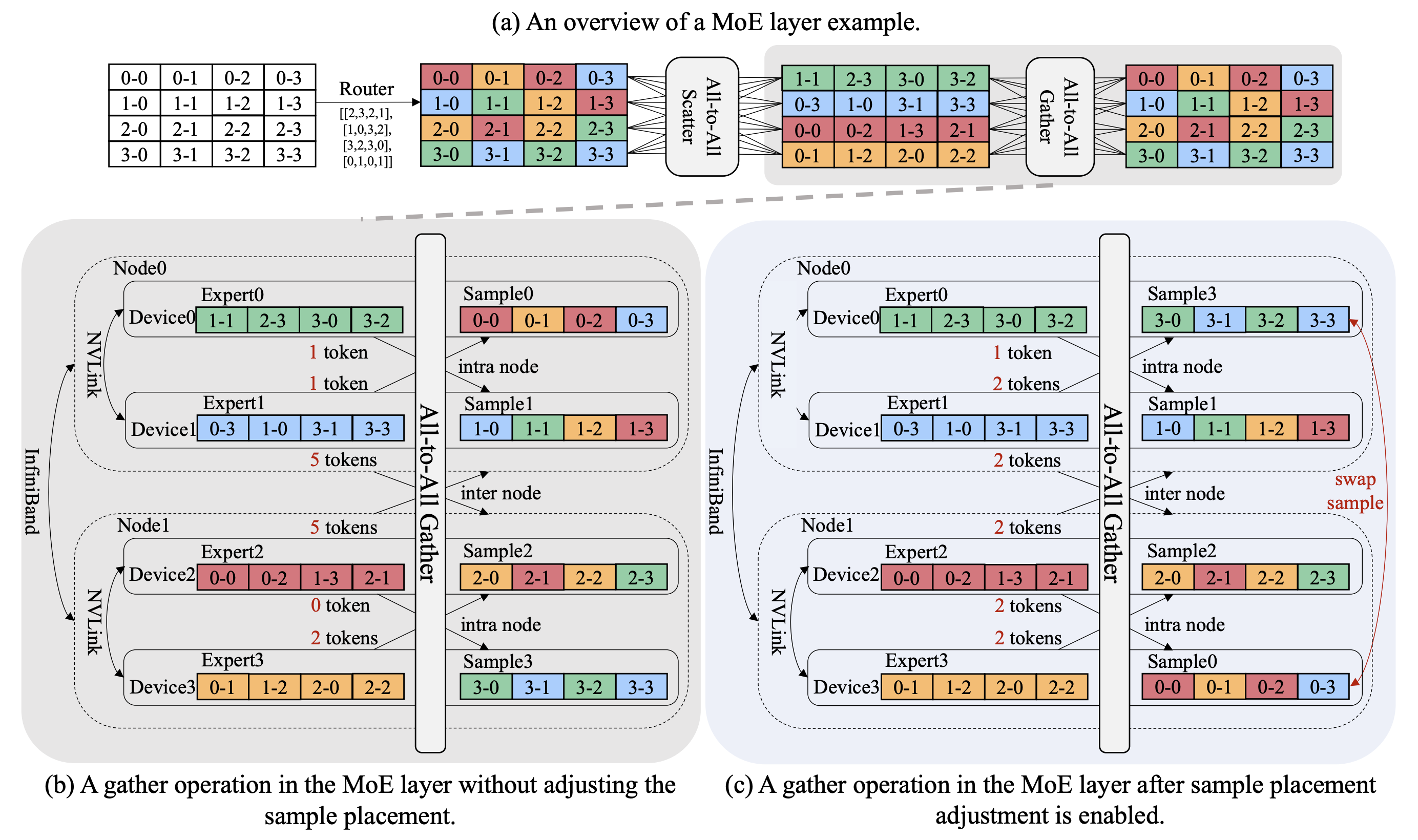
NetMoE: Accelerating MoE Training through Dynamic Sample Placement
Xinyi Liu, Yujie Wang, Fangcheng Fu, Xupeng Miao, Shenhan Zhu, Xiaonan Nie, Bin Cui
[ICLR 2025 (Spotlight 5.1%) | Second Author] International Conference on Learning Representations 2025 Spotlight
During the training of Mixture of Experts (MoE) models, All-to-All communication has become a notable challenge to training efficiency. In this paper, we find that tokens in the same training sample have certain levels of locality in expert routing. Motivated by this, we develop NetMoE, which takes such locality into account and dynamically rearranges the placement of training samples to minimize All-to-All communication costs. Experiments show the superior efficiency of NetMoE over state-of-the-art MoE training frameworks.
NetMoE: Accelerating MoE Training through Dynamic Sample Placement
Xinyi Liu, Yujie Wang, Fangcheng Fu, Xupeng Miao, Shenhan Zhu, Xiaonan Nie, Bin Cui
[ICLR 2025 (Spotlight 5.1%) | Second Author] International Conference on Learning Representations 2025 Spotlight
During the training of Mixture of Experts (MoE) models, All-to-All communication has become a notable challenge to training efficiency. In this paper, we find that tokens in the same training sample have certain levels of locality in expert routing. Motivated by this, we develop NetMoE, which takes such locality into account and dynamically rearranges the placement of training samples to minimize All-to-All communication costs. Experiments show the superior efficiency of NetMoE over state-of-the-art MoE training frameworks.
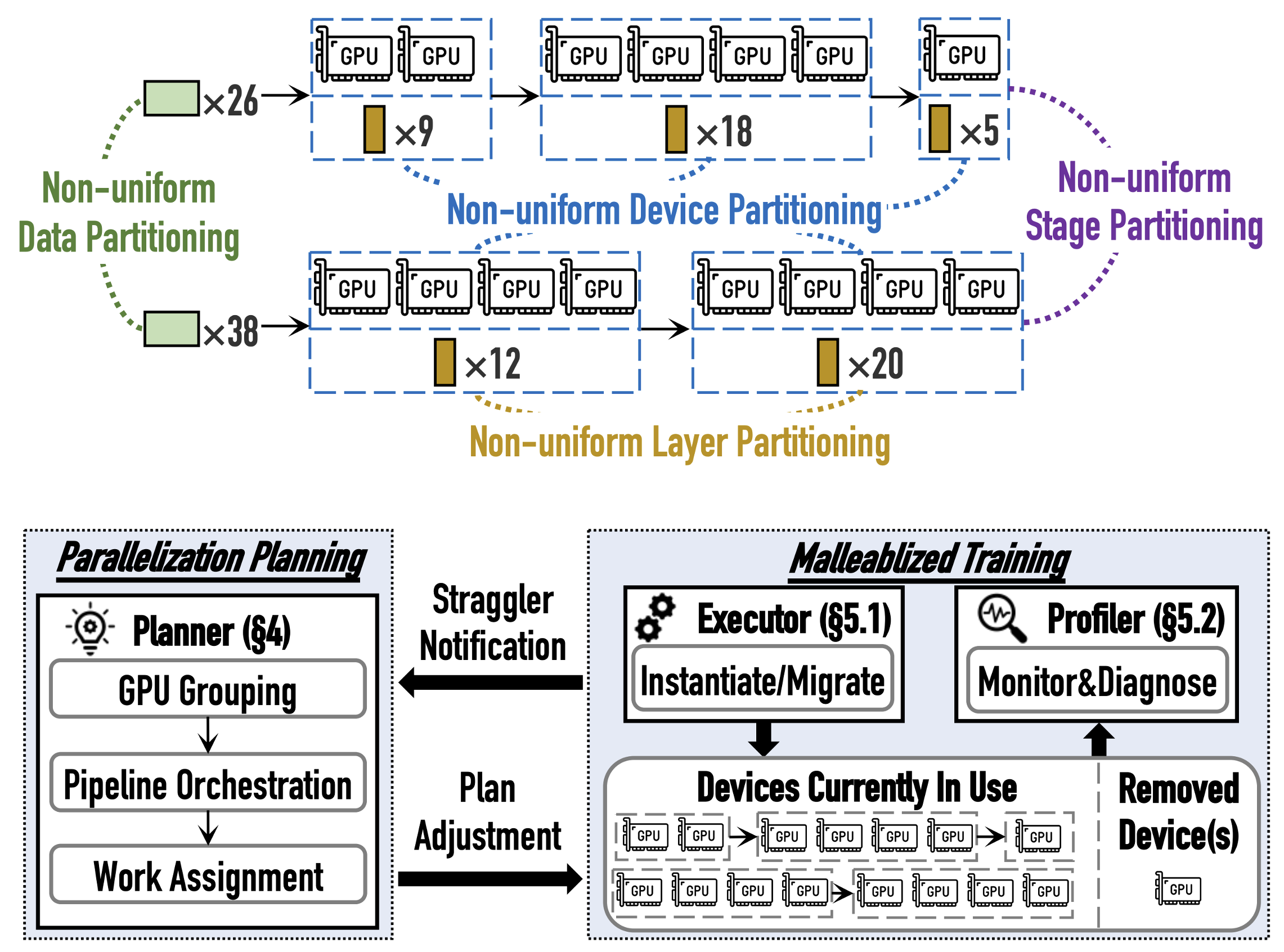
Malleus: Straggler-Resilient Hybrid Parallel Training of Large-scale Models via Malleable Data and Model Parallelization
Haoyang Li, Fangcheng Fu, Hao Ge, Sheng Lin, Xuanyu Wang, Jiawen Niu, Yujie Wang, Hailin Zhang, Xiaonan Nie, Bin Cui
[SIGMOD 2025 (CCF-A)] ACM International Conference on Management of Data 2025
As model size and training data grow, the reliance on GPUs increases, raising the risk of dynamic stragglers that some devices lag behind in performance occasionally. We propose Malleus, a straggler-resilient hybrid parallel training framework for large-scale models. Malleus captures the dynamic straggler issues at the nuanced, per-GPU granularity during training, and adapts in real-time to stragglers by adjusting GPU parallelization, pipeline stages, model layers, and data. Besides, it efficiently migrates model states without disrupting training stability.
Malleus: Straggler-Resilient Hybrid Parallel Training of Large-scale Models via Malleable Data and Model Parallelization
Haoyang Li, Fangcheng Fu, Hao Ge, Sheng Lin, Xuanyu Wang, Jiawen Niu, Yujie Wang, Hailin Zhang, Xiaonan Nie, Bin Cui
[SIGMOD 2025 (CCF-A)] ACM International Conference on Management of Data 2025
As model size and training data grow, the reliance on GPUs increases, raising the risk of dynamic stragglers that some devices lag behind in performance occasionally. We propose Malleus, a straggler-resilient hybrid parallel training framework for large-scale models. Malleus captures the dynamic straggler issues at the nuanced, per-GPU granularity during training, and adapts in real-time to stragglers by adjusting GPU parallelization, pipeline stages, model layers, and data. Besides, it efficiently migrates model states without disrupting training stability.
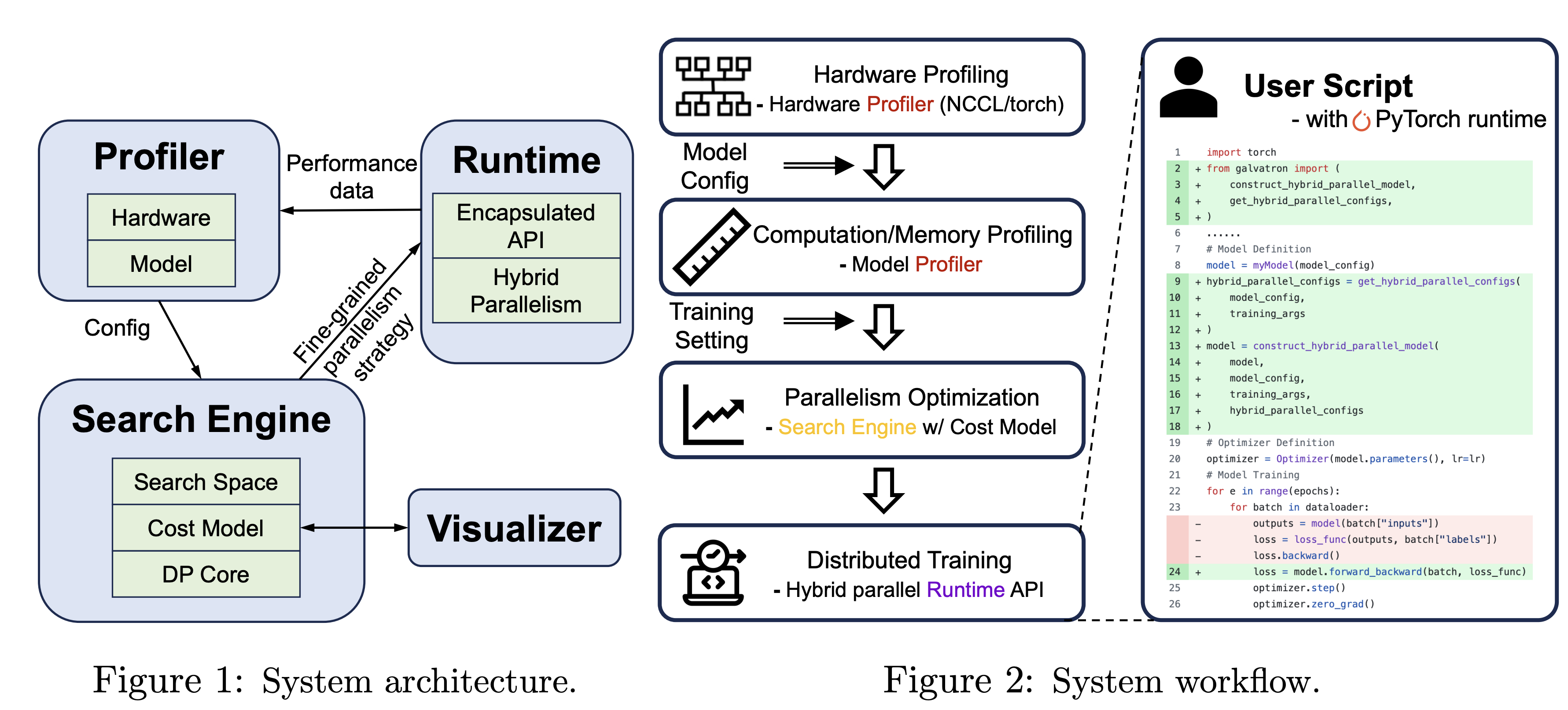
Galvatron: An Automatic Distributed System for Efficient Foundation Model Training
Xinyi Liu*, Yujie Wang*, Shenhan Zhu*, Fangcheng Fu, Qingshuo Liu, Guangming Lin, Bin Cui (* equal contribution)
[Under Review] 2025
Galvatron is a distributed system for efficiently training large-scale Foundation Models. It overcomes the complexities of selecting optimal parallelism strategies by automatically identifying the most efficient hybrid strategy, incorporating data, tensor, pipeline, sharded data, and sequence parallelism, along with recomputation. This open-source system offers user-friendly interfaces and comprehensive documentation, making complex distributed training accessible and efficient. Benchmarking on various clusters demonstrates Galvatron's superior throughput compared to existing frameworks.
Galvatron: An Automatic Distributed System for Efficient Foundation Model Training
Xinyi Liu*, Yujie Wang*, Shenhan Zhu*, Fangcheng Fu, Qingshuo Liu, Guangming Lin, Bin Cui (* equal contribution)
[Under Review] 2025
Galvatron is a distributed system for efficiently training large-scale Foundation Models. It overcomes the complexities of selecting optimal parallelism strategies by automatically identifying the most efficient hybrid strategy, incorporating data, tensor, pipeline, sharded data, and sequence parallelism, along with recomputation. This open-source system offers user-friendly interfaces and comprehensive documentation, making complex distributed training accessible and efficient. Benchmarking on various clusters demonstrates Galvatron's superior throughput compared to existing frameworks.
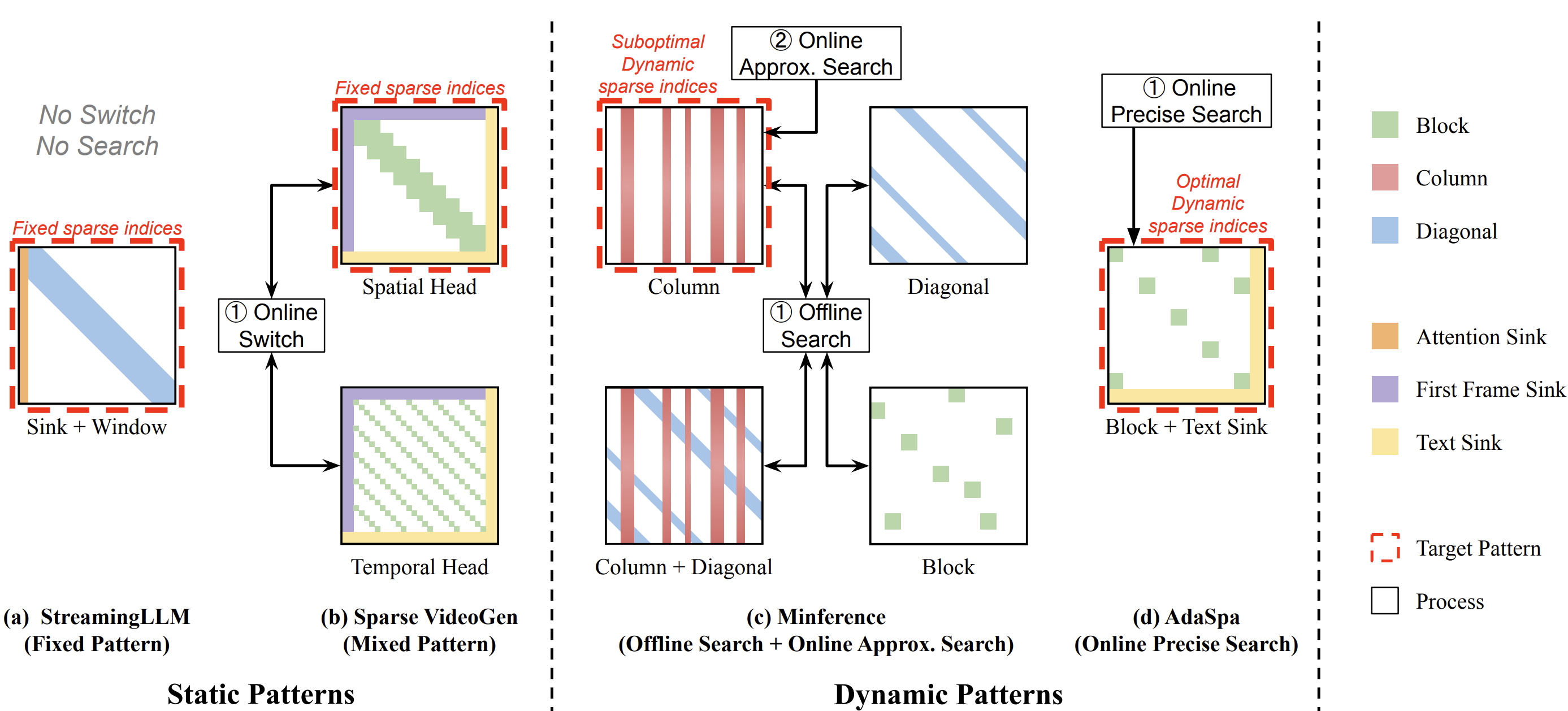
Training-free and Adaptive Sparse Attention for Efficient Long Video Generation
Yifei Xia, Suhan Ling, Fangcheng Fu, Yujie Wang, Huixia Li, Xuefeng Xiao, Bin Cui
[ICCV 2025 (CCF-A) | Fourth Author] International Conference on Computer Vision 2025
Generating high-fidelity long videos with Diffusion Transformers (DiTs) is often hindered by significant latency, primarily due to the computational demands of attention mechanisms. We propose AdaSpa, the first Dynamic Pattern and Online Precise Search sparse attention method. Firstly, to realize the Dynamic Pattern, we introduce a blockified pattern to efficiently capture the hierarchical sparsity inherent in DiTs. Secondly, to enable Online Precise Search, we propose the Fused LSE-Cached Search with Head-adaptive Hierarchical Block Sparse Attention. Experiments validate AdaSpa's substantial acceleration while preserving video quality.
Training-free and Adaptive Sparse Attention for Efficient Long Video Generation
Yifei Xia, Suhan Ling, Fangcheng Fu, Yujie Wang, Huixia Li, Xuefeng Xiao, Bin Cui
[ICCV 2025 (CCF-A) | Fourth Author] International Conference on Computer Vision 2025
Generating high-fidelity long videos with Diffusion Transformers (DiTs) is often hindered by significant latency, primarily due to the computational demands of attention mechanisms. We propose AdaSpa, the first Dynamic Pattern and Online Precise Search sparse attention method. Firstly, to realize the Dynamic Pattern, we introduce a blockified pattern to efficiently capture the hierarchical sparsity inherent in DiTs. Secondly, to enable Online Precise Search, we propose the Fused LSE-Cached Search with Head-adaptive Hierarchical Block Sparse Attention. Experiments validate AdaSpa's substantial acceleration while preserving video quality.
2024
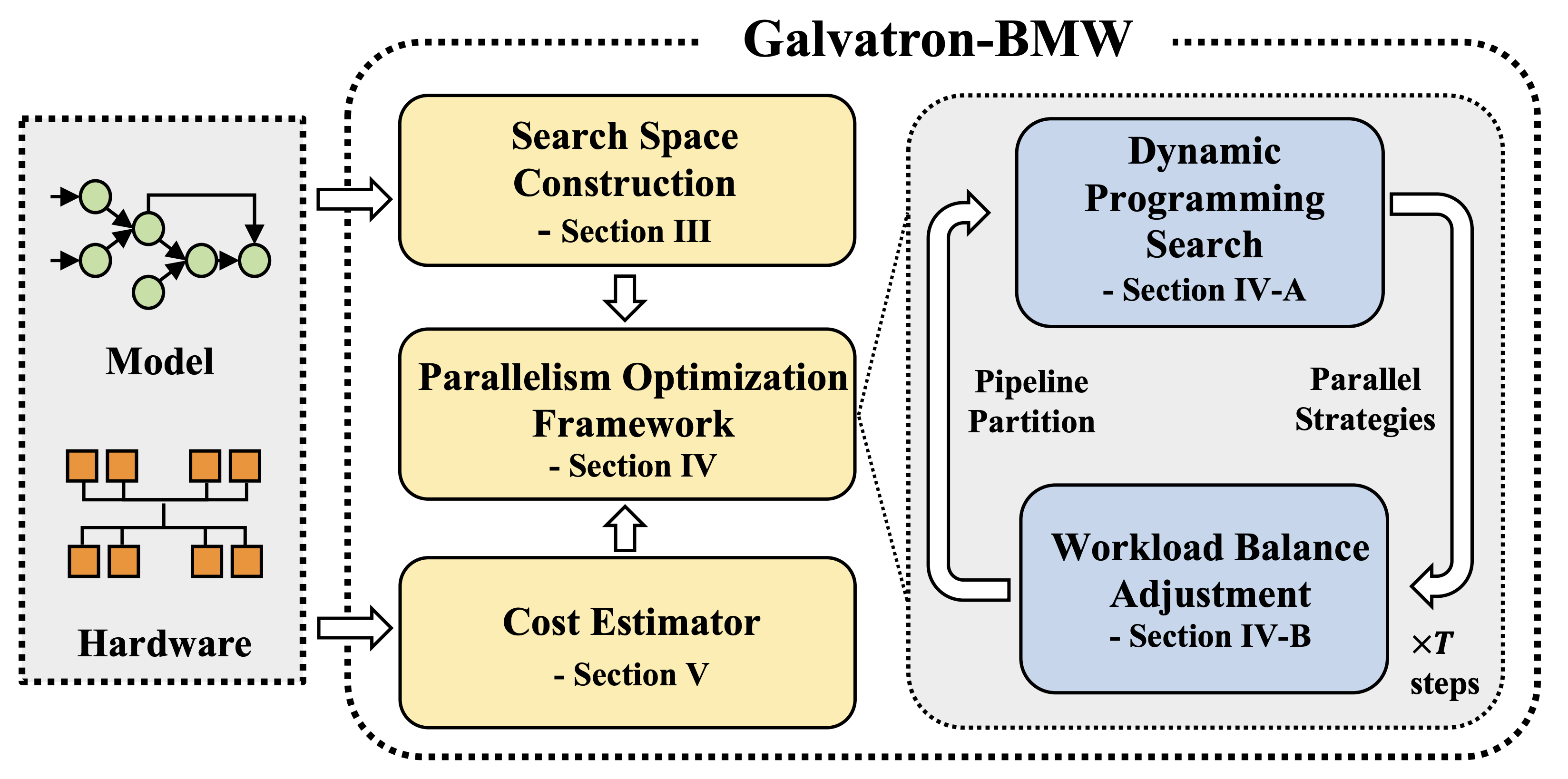
Improving Automatic Parallel Training via Balanced Memory Workload Optimization
Yujie Wang, Youhe Jiang, Xupeng Miao, Fangcheng Fu, Shenhan Zhu, Xiaonan Nie, Yaofeng Tu, Bin Cui
[TKDE 2024 (CCF-A) | First Author] IEEE Transactions on Knowledge and Data Engineering 2024
Efficiently training Transformer models across multiple GPUs remains a complex challenge due to the abundance of parallelism options. In this paper, we present Galvatron-BMW, a novel system framework that integrates multiple prevalent parallelism dimensions, which not only targets automatic parallelism optimization for large-scale Transformer models training, but also considers the Balancing trade-off between Memory and computation Workloads across devices through a novel bi-objective optimization framework. Experiments demonstrate the efficiency of our system.
Improving Automatic Parallel Training via Balanced Memory Workload Optimization
Yujie Wang, Youhe Jiang, Xupeng Miao, Fangcheng Fu, Shenhan Zhu, Xiaonan Nie, Yaofeng Tu, Bin Cui
[TKDE 2024 (CCF-A) | First Author] IEEE Transactions on Knowledge and Data Engineering 2024
Efficiently training Transformer models across multiple GPUs remains a complex challenge due to the abundance of parallelism options. In this paper, we present Galvatron-BMW, a novel system framework that integrates multiple prevalent parallelism dimensions, which not only targets automatic parallelism optimization for large-scale Transformer models training, but also considers the Balancing trade-off between Memory and computation Workloads across devices through a novel bi-objective optimization framework. Experiments demonstrate the efficiency of our system.
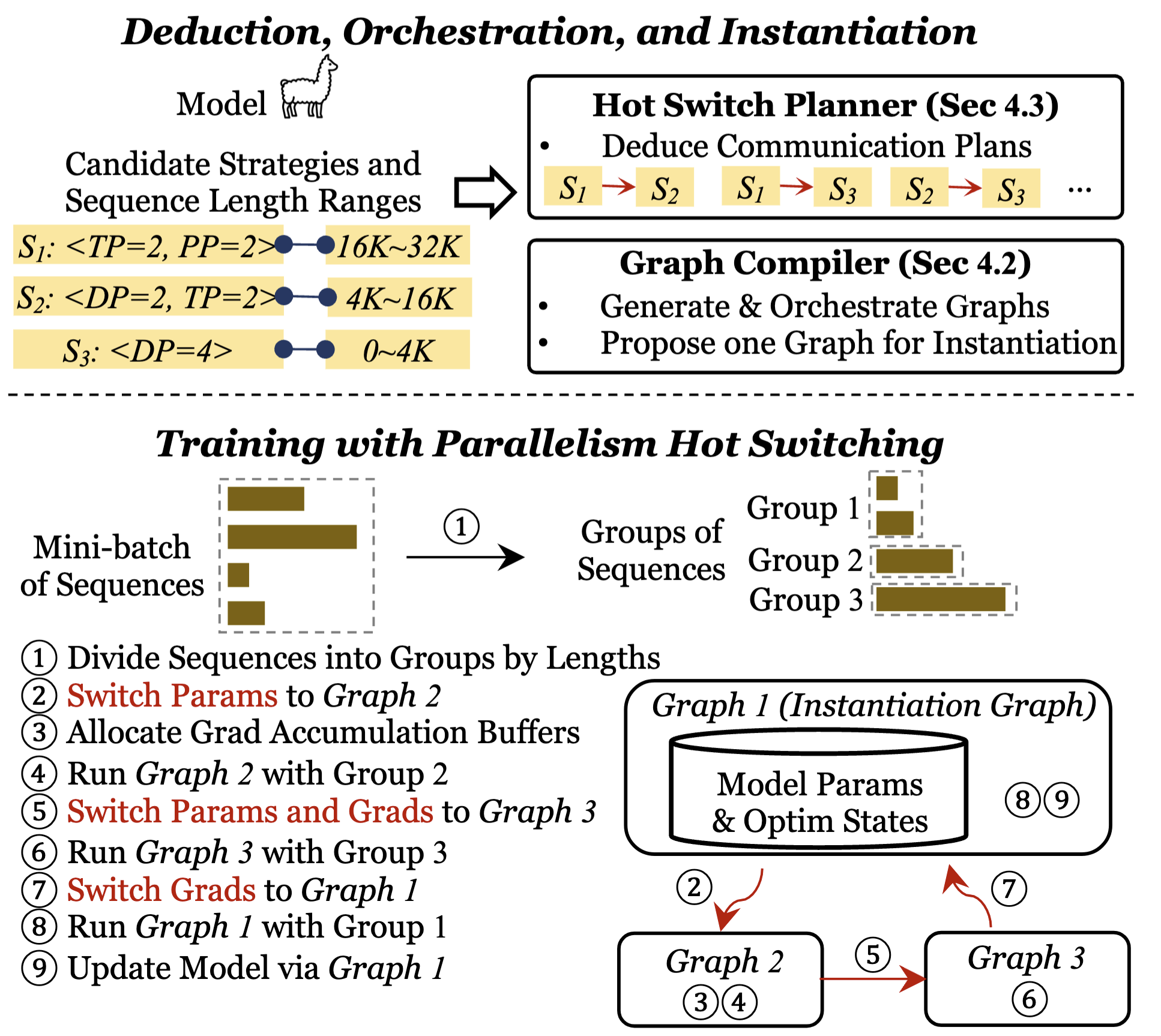
Enabling Parallelism Hot Switching for Efficient Training of Large Language Models
Hao Ge, Fangcheng Fu, Haoyang Li, Xuanyu Wang, Sheng Lin, Yujie Wang, Xiaonan Nie, Hailin Zhang, Xupeng Miao, Bin Cui
[SOSP 2024 (CCF-A)] Proceedings of the ACM SIGOPS 30th Symposium on Operating Systems Principles 2024
Training large-scale deep learning models requires parallelizing across multiple devices. Current systems assume uniform workloads and adopt a static parallelism strategy throughout one training process, but this fails for sequence inputs with varying lengths, leading to sub-optimal performance. This paper introduces HotSPa, a system that uses multiple parallelism strategies within a mini-batch. HotSPa partitions sequences into multiple groups, applies different strategies to each group, and enables dynamic switching between strategies by transferring model parameters and gradients in real-time.
Enabling Parallelism Hot Switching for Efficient Training of Large Language Models
Hao Ge, Fangcheng Fu, Haoyang Li, Xuanyu Wang, Sheng Lin, Yujie Wang, Xiaonan Nie, Hailin Zhang, Xupeng Miao, Bin Cui
[SOSP 2024 (CCF-A)] Proceedings of the ACM SIGOPS 30th Symposium on Operating Systems Principles 2024
Training large-scale deep learning models requires parallelizing across multiple devices. Current systems assume uniform workloads and adopt a static parallelism strategy throughout one training process, but this fails for sequence inputs with varying lengths, leading to sub-optimal performance. This paper introduces HotSPa, a system that uses multiple parallelism strategies within a mini-batch. HotSPa partitions sequences into multiple groups, applies different strategies to each group, and enables dynamic switching between strategies by transferring model parameters and gradients in real-time.
2023
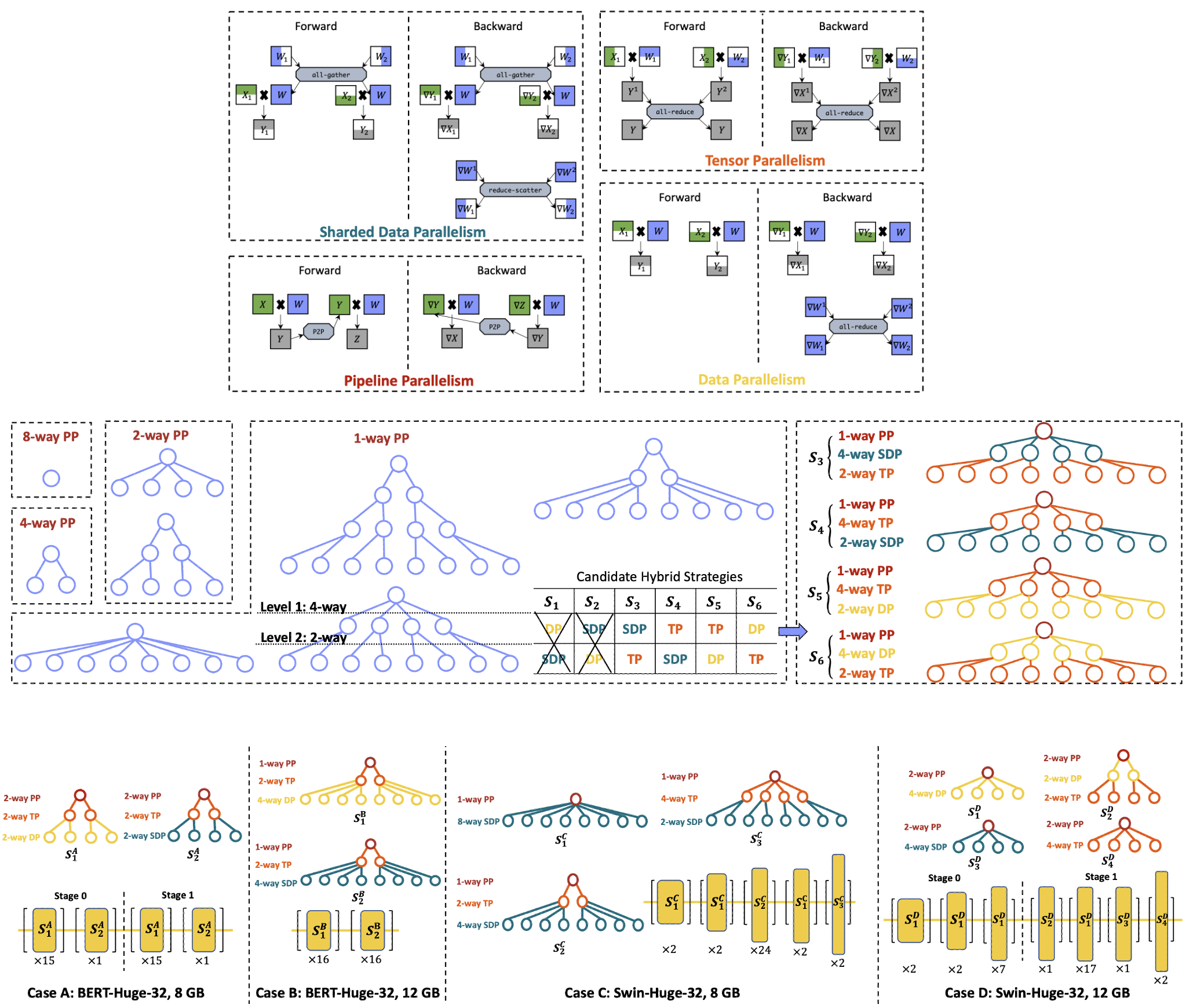
Galvatron: Efficient Transformer Training over Multiple GPUs Using Automatic Parallelism
Xupeng Miao*, Yujie Wang*, Youhe Jiang*, Chunan Shi, Xiaonan Nie, Hailin Zhang, Bin Cui (* equal contribution)
[VLDB 2023 (CCF-A) | Co-First Author] Proceedings of the VLDB Endowment 2023
To train large Transformer models over multiple GPUs efficiently, we propose Galvatron, a new automatic parallelism system that incorporates multiple popular parallelism dimensions and automatically finds the most efficient hybrid parallelism strategy. To better explore such a rarely huge search space, we 1) involve a decision tree to make decomposition and pruning based on some reasonable intuitions, and then 2) design a dynamic programming search algorithm to generate the optimal plan. Experiments show the effectiveness and efficiency of Galvatron.
Galvatron: Efficient Transformer Training over Multiple GPUs Using Automatic Parallelism
Xupeng Miao*, Yujie Wang*, Youhe Jiang*, Chunan Shi, Xiaonan Nie, Hailin Zhang, Bin Cui (* equal contribution)
[VLDB 2023 (CCF-A) | Co-First Author] Proceedings of the VLDB Endowment 2023
To train large Transformer models over multiple GPUs efficiently, we propose Galvatron, a new automatic parallelism system that incorporates multiple popular parallelism dimensions and automatically finds the most efficient hybrid parallelism strategy. To better explore such a rarely huge search space, we 1) involve a decision tree to make decomposition and pruning based on some reasonable intuitions, and then 2) design a dynamic programming search algorithm to generate the optimal plan. Experiments show the effectiveness and efficiency of Galvatron.
2022
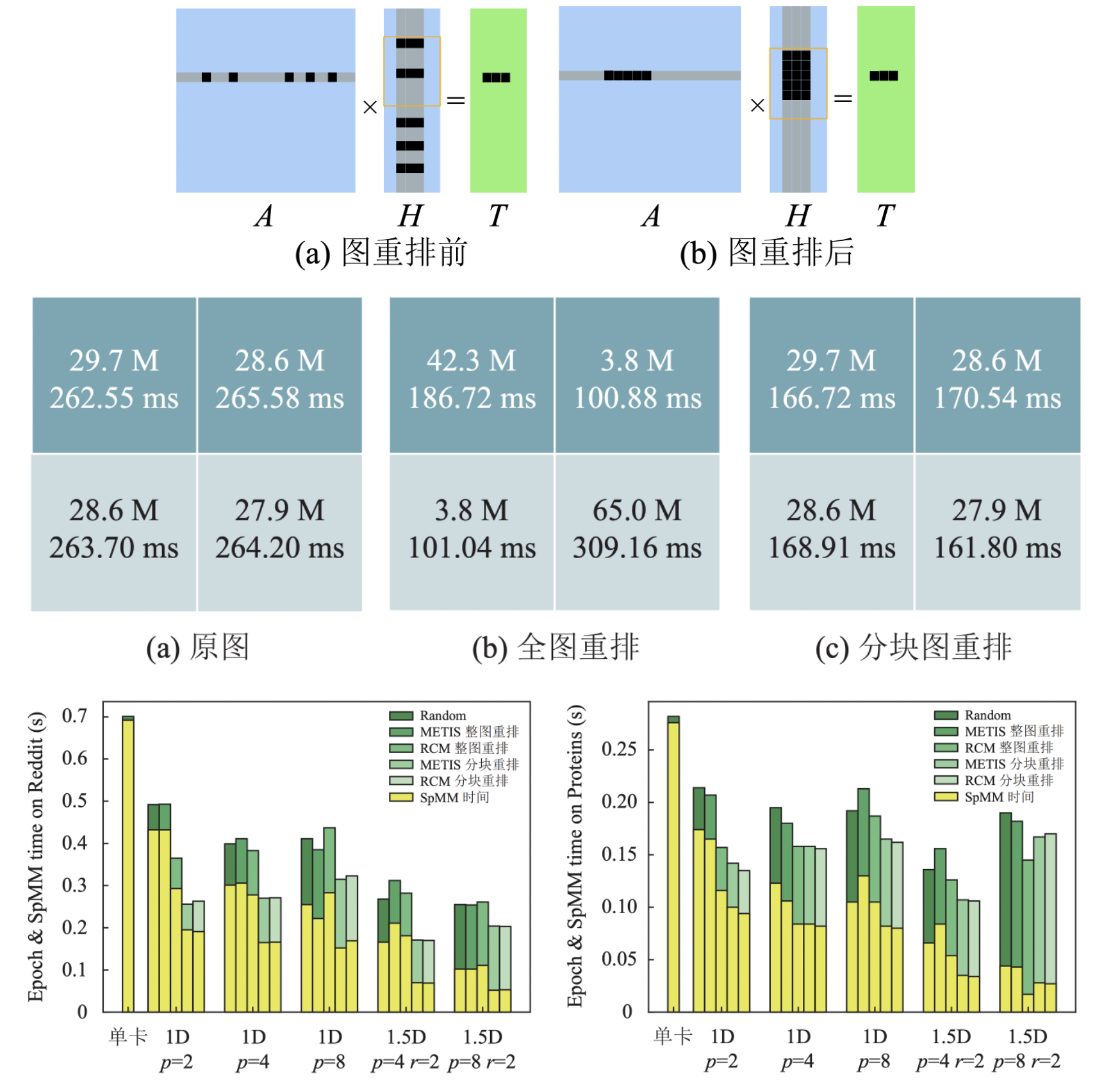
Graph Neural Network Training Acceleration for Multi-GPUs
Xupeng Miao, Yujie Wang, Jia Shen, Yingxia Shao, Bin Cui
[JOS 2022 (CCF-A) | Second Author] Journal of Software 2022
Graph neural networks (GNNs) are gaining attention, but performing efficient large GNN training over GPUs remains a challenge. This work proposes a high-performance GNN training framework for multi-GPUs. We explore different GNN partition strategies for multi-GPUs, and investigate the influence of different graph ordering patterns on the GPU performance during the calculation process of GNNs. Moreover, block-sparsity-aware optimization methods are put forward for GPU memory access. The experiments on four large-scale GNN datasets demonstrate the efficiency of our framework compared to existing system such as DGL.
Graph Neural Network Training Acceleration for Multi-GPUs
Xupeng Miao, Yujie Wang, Jia Shen, Yingxia Shao, Bin Cui
[JOS 2022 (CCF-A) | Second Author] Journal of Software 2022
Graph neural networks (GNNs) are gaining attention, but performing efficient large GNN training over GPUs remains a challenge. This work proposes a high-performance GNN training framework for multi-GPUs. We explore different GNN partition strategies for multi-GPUs, and investigate the influence of different graph ordering patterns on the GPU performance during the calculation process of GNNs. Moreover, block-sparsity-aware optimization methods are put forward for GPU memory access. The experiments on four large-scale GNN datasets demonstrate the efficiency of our framework compared to existing system such as DGL.
2021
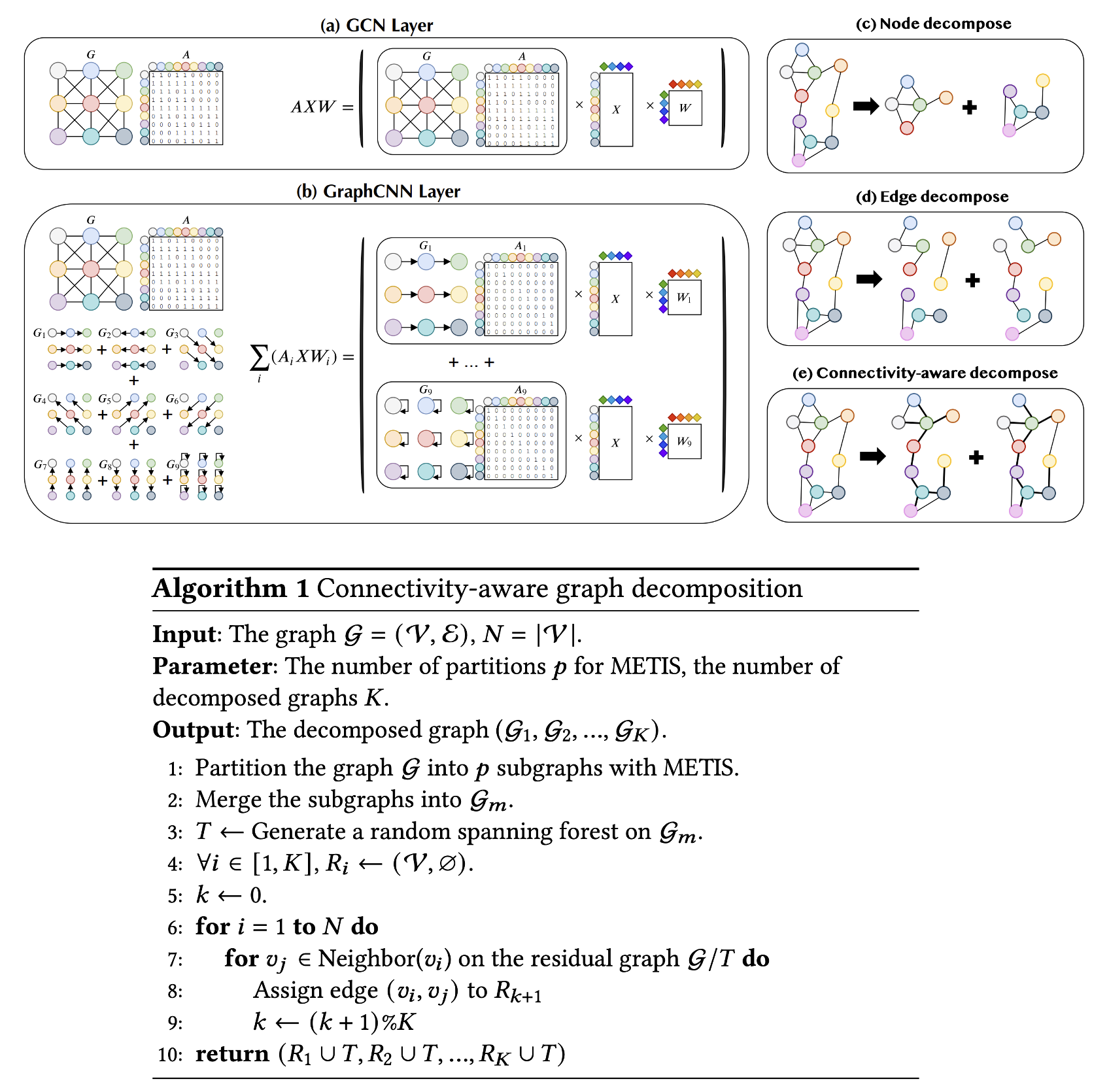
DeGNN: Improving Graph Neural Networks with Graph Decomposition
Xupeng Miao, Nezihe Merve Gürel, Wentao Zhang, Zhichao Han, Bo Li, Wei Min, Susie Xi Rao, Hansheng Ren, Yinan Shan, Yingxia Shao, Yujie Wang, Fan Wu, Hui Xue, Yaming Yang, Zitao Zhang, Yang Zhao, Shuai Zhang, Yujing Wang, Bin Cui, Ce Zhang
[SIGKDD 2021 (CCF-A)] Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining 2021
Graph convolutional networks (GCNs) are key in graph mining but face challenges such as diverse performance across applications, oversmoothing, and non-robustness. This paper introduces DeGNN, a graph decomposition approach to improve GCN performance. We propose an automatic, connectivity-aware decomposition algorithm and provide a theoretical explanation from an information-theoretic perspective. We show that graph decomposition can reduce information loss in deeper GCNs, mitigating the exponential convergence of mutual information.
DeGNN: Improving Graph Neural Networks with Graph Decomposition
Xupeng Miao, Nezihe Merve Gürel, Wentao Zhang, Zhichao Han, Bo Li, Wei Min, Susie Xi Rao, Hansheng Ren, Yinan Shan, Yingxia Shao, Yujie Wang, Fan Wu, Hui Xue, Yaming Yang, Zitao Zhang, Yang Zhao, Shuai Zhang, Yujing Wang, Bin Cui, Ce Zhang
[SIGKDD 2021 (CCF-A)] Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining 2021
Graph convolutional networks (GCNs) are key in graph mining but face challenges such as diverse performance across applications, oversmoothing, and non-robustness. This paper introduces DeGNN, a graph decomposition approach to improve GCN performance. We propose an automatic, connectivity-aware decomposition algorithm and provide a theoretical explanation from an information-theoretic perspective. We show that graph decomposition can reduce information loss in deeper GCNs, mitigating the exponential convergence of mutual information.